Online tracking: A 1-million-site measurement and analysis is the largest and most detailed measurement of online tracking to date. We measure stateful (cookie-based) and stateless (fingerprinting-based) tracking, the effect of browser privacy tools, and "cookie syncing".
This measurement is made possible by our web measurement tool OpenWPM, a mature platform that enables fully automated web crawls using a full-fledged and instrumented browser.
About
Authors: Steven Englehardt and Arvind Narayanan of Princeton University ({ste,arvindn}@cs.princeton.edu)
The study is part of the Princeton University's WebTAP project.
Tracking Results
The Long Tail of Online Tracking

During our January 2016 measurement of the top 1 million sites, our tool made over 90 million requests, assembling the largest dataset (to our knowledge) used for studying web tracking. With this scale we can answer many web tracking questions: Who are the largest trackers? Which sites embed the largest number of trackers? Which tracking technologies are used, and who is using them? and many more.
Findings
The total number of third parties present on at least two first parties is over 81,000, but the prevalence quickly drops off. Only 123 of these 81,000 are present on more than 1% of sites. This suggests that the number of third parties that a regular user will encounter on a daily basis is relatively small. The effect is accentuated when we consider that different third parties may be owned by the same entity. All of the top 5 third parties, as well as 12 of the top 20, are Google-owned domains. In fact, Google, Facebook, and Twitter are the only third-party entities present on more than 10% of sites.
Third parties and HTTPS adoption

Third parties are a major roadblock to HTTPS adoption; insecure third-party resources loaded on secure sites (i.e. mixed content on HTTPS sites) will either be blocked or cause the browser to display security warnings. We find that a large number of third parties (54%) are only ever loaded over HTTP. A significant fraction of HTTP-default sites (26%) embed resources from at least one of the HTTP-only third parties on their homepage. These sites would be unable to upgrade to HTTPS without browsers displaying mixed content errors to their users, the majority of which (92%) would contain active content which would be blocked.
Around 78,000 first-party sites currently support HTTPS by default on their home pages. Nearly of these 8% load with mixed content warnings, of which 12% are caused by third-party trackers.
News sites have the most trackers

The level of tracking on different categories of websites varies considerably -- by almost an order of magnitude. The figure on the right shows average counts of tracking and non-tracking third parties per site for 100 of the top sites in each category.
Why is there so much variation? With the exception of the adult category, the sites on the low end of the spectrum are mostly sites which belong to government organizations, universities, and non-profit entities. This suggests that websites may be able to forgo advertising and tracking due to the presence of funding sources external to the web. Sites on the high end of the spectrum are largely those which provide editorial content. Since many of these sites provide articles for free, and lack an external funding source, they are pressured to monetize page views with significantly more advertising.
Does tracking protection work?
Users have two main ways to reduce their exposure to tracking: the browser's built in privacy features and extensions such as Ghostery or uBlock Origin. We used two test measurements of the top 55k sites with different blocking tools enabled: one with Ghostery enabled and set to block trackers, and one with Firefox's third-party cookie blocker enabled.
Findings
Firefox's third-party cookie blocking is very effective, only 237 sites (0.4%) have any third-party cookies set from a domain other than the landing page of the site. Most of these are for benign reasons, such as redirecting to the U.S. version of a non-U.S. site. We did find a handful of exceptions, including 32 that contained ID cookies. These sites appeared to be deliberately redirecting the landing page to a separate domain before redirecting back to the initial domain. Ghostery was effective at reducing both the number of third parties and ID cookies. The average number of third-party includes went down from 17.7 to 3.3, of which just 0.3 had third-party cookies (0.1 with IDs).
Fingerprinting Results

The growth (and diversity) of device fingerprinting.
We examine four types of device fingerprinting. We provide updated Canvas fingerprinting measurements from our 2014 study. We also present findings on three techniques that have never been measured before: AudioContext fingerprinting, Canvas-Font fingerprinting, and WebRTC fingerprinting. The table on the right shows the percentage of sites on which each technique appears for different site ranks within the Alexa top 1 million.
Canvas Fingerprinting
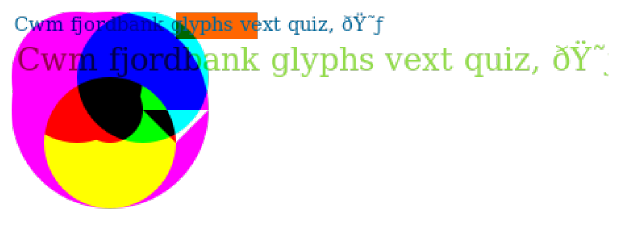
The HTML Canvas allows web application to draw graphics in real time, with functions to support drawing shapes, arcs, and text to a custom canvas element. Differences in font rendering, smoothing, anti-aliasing, as well as other device features cause devices to draw the image differently. This allows the resulting pixels to be used a part of a device fingerprint. The image on the left is a representative example of the types of canvas images used by fingerprinting scripts.
Findings
We found canvas fingerprinting on 14,371 sites, caused by scripts loaded from about 400 different domains. Comparing our results with those from our 2014 collaboration with researchers at KU Leuven, we find three important trends. First, the most prominent trackers have by-and-large stopped using it, suggesting that the public backlash following that study was effective. Second, the overall number of domains employing it has increased considerably, indicating that knowledge of the technique has spread and that more obscure trackers are less concerned about public perception. Third, the use has shifted from behavioral tracking to fraud detection, in line with the ad industry's self-regulatory norm regarding acceptable uses of fingerprinting.
Full list of sites using Canvas Fingerprinting » Full script list (tsv) »
AudioContext Fingerprinting

Fingerprinting techniques typically aren't used in isolation but rather in conjunction with each other. By looking for unusual behavior in tracking scripts (e.g., use of new APIs) we found several fingerprinting scripts utilizing AudioContext and related interfaces. A manual analysis of these scripts suggest that trackers are attempting to utilize the Audio API to fingerprint users in multiple ways.
The figure on the right shows two different AudioNode configurations found during our study. In both configurations an audio signal is generated by an oscillator and the resulting signal is hashed after processing to create an identifier. This does not require access to the device's microphone, and instead relies on differences in the way the generated signal is processed. You can test your own device's Audio API fingerprint using our demonstration page here.
Findings
In total, we foundAudioContext fingerprinting of the type shown in the figure to the right in just 3 scripts present on 67 sites. Only two of these scripts appeared to be actively using the technique. Futher research is necessary to examine the stability and uniqueness of the fingerprint.
Full list of sites using AudioContext Fingerprinting » Full script list (tsv) »
WebRTC Local IP Discovery
WebRTC is a framework for peer-to-peer Real Time Communication in the browser, and accessible via Javascript. To discover the best path between peers, each peer collects all available candidate addresses, including addresses from the local network interfaces (such as ethernet or WiFi) and addresses from the public side of the NAT and makes them available to the web application without explicit permission from the user. A fingerprinter can leverage these addresses to track users.
Findings
We found WebRTC being used to discover local IP addresses on 715 of the top 1 million sites. The vast majority of these instances were caused by third-party trackers.
Full list of Local IP Discovery scripts » Full script list (tsv) »
Canvas-Font Fingerprinting
Javascript and Flash have both been used to enumerate fonts in the browser and use them to fingerprint users. The HTML Canvas API provides a third method to deduce the fonts installed on a particular browser. The canvas rendering interface exposes a measureText method, which provides the resulting width of text drawn to canvas. A script can attempt to draw text using a large number of fonts and then measure the resulting width. If the text's width is not equal to the width of the text using a default font (which would indicate that the browser does not have the tested font), then the script can conclude that the browser does have that font available.
Findings
In our measurement, we found canvas-based font fingerprinting on 3,250 first-party sites. A single third party (MediaMath) was responsible for the majority of font fingerprinting events, however a total of 5 other third parties were found to use the technique.
Full list of sites using Canvas-Font Fingerprinting » Full script list (tsv) »
Studies Using OpenWPM
Data
The data is available as bzipped PostgreSQL dumps. The schema file used in all of the datasets is available here.
| Dataset | Comments |
|---|---|
| 1 Million Site Stateless | Parallel Stateless Crawl |
| 100k Site Stateful | Parallel Stateful Crawl -- 10,000 site seed profile |
| 10k Site ID Detection (1) | Sequential Stateful Crawl -- Flash enabled -- Synced with ID Detection (2) |
| 10k Site ID Detection (2) | Sequential Stateful Crawl -- Flash enabled -- Synced with ID Detection (1) |
| 55k Site Stateless with cookie blocking | Parallel Stateless Crawl -- Firefox set to block all third-party cookies |
| 55k Site Stateless with Ghostery | Parallel Stateless Crawl -- Ghostery extension installed and set to block all possible trackers |
| 55k Site Stateless with HTTPS Everywhere | Parallel Stateless Crawl -- HTTPS Everywhere installed |
Code
Contact
| Steven Englehardt | ste@cs.princeton.edu |
| Arvind Narayanan | arvindn@cs.princeton.edu |